Configurar correctamente nuestro archivo robots.txt nos permitirá afinar nuestro SEO técnico y optimizar el crawl-budget, para que los buscadores empleen el presupuesto de rastreo en las páginas de nuestro sitio web que nos interesan. ¿Qué es y para qué sirve el robots.txt? El robots.txt es un archivo que se puede incluir en la raíz del […]

Configurar correctamente nuestro archivo robots.txt nos permitirá afinar nuestro SEO técnico y optimizar el crawl-budget, para que los buscadores empleen el presupuesto de rastreo en las páginas de nuestro sitio web que nos interesan.
¿Qué es y para qué sirve el robots.txt?
El robots.txt es un archivo que se puede incluir en la raíz del sitio web, que proporciona información a los rastreadores de los buscadores (también llamados bots o robots), sobre las páginas o archivos que deberían rastrear o no de la web.
¿Qué son los rastreadores de los buscadores y por qué hacen caso a robots.txt?
Los rastreadores de los buscadores, también conocidos como crawlers, robots o bots de rastreo, son servicios o user-agents según la terminología de robots.txt, que navegan por los sitios web, para analizarlos y recolectar información. Con esa información, los motores de búsqueda, como Google, evalúan cada sitio web, sus páginas y contenido, para determinar su posicionamiento en los SERPs.
La mayoría de los rastreadores cumplen las directivas que se indican en los archivos robots.txt, pero no todos.
El robot de Google y los rastreadores de los buscadores web más populares, como Bing, Yahoo, Baidu o Yandex sí cumplen las instrucciones de los archivos robots.txt, pero puede que otros rastreadores no lo hagan.
¿Puedo evitar que se indexe una página con robots.txt?
Ojo, no es lo mismo impedir que el bot de Google rastree una página, que evitar que la indexe o que impedir que tanto rastreadores como usuarios puedan acceder a ella.
Con robots.txt podemos conseguir que Google u otros buscadores no rastreen determinadas páginas, evitando que tu sitio web se sobrecargue con solicitudes a páginas o contenido que no nos interesa que sean rastreadas. Conseguiremos así que los rastreadores no pierdan tiempo en dichas páginas o contenido, que posiblemente tampoco queremos que se indexen, optimizando así nuestro SEO respecto al crawl-budget.
Pero robots.txt no es un mecanismo para mantener una página web fuera del índice de Google o de otro buscador. Si no quieres que una página se indexe en Google u otros buscadores, utiliza directivas noindex o protégela con una contraseña.
¿Qué es el crawl-budget y por qué me puede interesar no rastrear todo mi sitio web?
Los recursos de los buscadores son finitos. Google y otros buscadores, tienen que asignar a sus rastreadores unos recursos, limitados por el tiempo u otros factores como la frecuencia de rastreo, para navegar y analizar cada sitio web. Denominamos crawl budget, o presupuesto de búsqueda, a los recursos finitos que un buscador asigna al rastreo de una web.
Google y otros buscadores no asignan el mismo crawl budget para todas las webs. Es lógico: por ejemplo un nuevo sitio web corporativo que acabamos de publicar o un pequeño blog, no van a tener los mismos recursos asignados para su rastreo, que un prestigioso peródico online. En función de la autoridad, accesibilidad, la calidad del contenido, e incluso la velocidad del sitio web, los buscadores asignan más o menos recursos para que sus crawlers rastreen sus diferentes páginas.
Tampoco el crawl-budget es igual de relevante para el SEO en todos los sitios webs, siendo más relevante en sites que tienen una gran cantidad de páginas (por ejemplo un ecommerce que incluya un catálogo con miles de referencias), que en webs de menos páginas, como una sencilla página corporativa.
Sobre todo si nuestra web tiene un tamaño, en cantidad de páginas y elementos indexables muy elevado, nos interesará indicarle a los buscadores, las páginas prioritarias para rastrear de nuestro site, aprovechando al máximo nuestro crawl budget.
En resumidas cuentas, podemos optimizar nuestro SEO indicando a Googlebot y al resto de rastreadores, como emplear el presupuesto de búsqueda en rastrear las páginas más valiosas de nuestro sitio web. Y ahí, es donde entra en juego robots.txt
Crea tu propio robots.txt
A continuación te damos todas las indicaciones para que puedas hacer y comprobar que tu archivo robots.txt.
Ubicación y codificación para tu archivo robots.txt
- Ubicación de robots.txt: El archivo robots.txt debe incluirse en la raíz del host del sitio web. Por ejemplo, para https://visualit.es/, el archivo robots.txt debe estar en https://visualit.es/robots.txt.
- Número de robots.txt por sitio web: Sólo puede haber un archivo robots.txt por sitio web, aunque tengamos una división por países o idiomas en formas de carpetas. Sí que podremos tener un archivo robots.txt por cada subdominio.
- Codificación y creación de robots.txt: Los archivos robots.txt deben estar codificados en UTF-8, que incluye ASCII. Para crearlos podemos emplear cualquier programa que cree un archivo de texto válido, como el Bloc de notas.
Sintaxis robots.txt
Una vez vistas las características, ubicación y codificación de robots,txt, pasamos sin dilación a ver las reglas de sintaxis generales:
Grupos: Los archivos robots.txt constan de uno o varios grupos, que a su vez se le aplican varias reglas o directivas (una directiva por línea). Por cada grupo se proporciona la siguiente información:
- User‑agent: indica a qué user-agent (robot de búsqueda) se aplica el grupo, por ejemplo Googlebot. Si se usa el asterisco (*) el grupo se aplicará a todos los rastreadores, salvo a los de AdsBot, que deberían incluirse de forma explícita si queremos bloquearlos.
Por cada grupo debe haber por lo menos una directiva Disallow o Allow: - Disallow: directiva indica los directorios o páginas del dominio raíz que el user‑agent no debe rastrear.
Si se bloquea una página, debe especificarse su nombre completo tal como se muestra en el navegador, mientras que, si se quiere impedir el acceso a un directorio, debe incluirse una barra (/) al final.
Se admite el carácter comodín * en el prefijo y en el sufijo, así como para sustituir toda la cadena.
De forma predeterminada, los user‑agent pueden rastrear todas las páginas y directorios que no estén bloqueados por una regla Disallow. - Allow: directiva indica los directorios o las páginas del dominio raíz que el user‑agent que se haya especificado en el grupo debe rastrear. Anula la directiva Disallow, por lo que se puede utilizar para permitir que se rastree un determinado subdirectorio o página de un directorio bloqueado
Los grupos terminan con una línea de user-agent o cuando se llega al final del archivo. Es posible que el último grupo no tenga ninguna regla, lo que implica que lo permite todo.
Sitemap: directiva recomendable para SEO, pues indica a los rastreadores la ubicación del sitemap de la web. Debe añadirse una URL completa, por ejemplo Sitemap:
https://visualit.es/sitemap.xml, y se puede añadir más de un sitemap (1 línea para cada sitemap). Los sitemaps son perfectamente complementarios con las directivas Allow y Disallow de robots,txt, y pueden mejorar el rastreo de sitios grandes o muy complejos, indicando las páginas más importantes que queremos que rastree e indexen los buscadores, frente al contenido que pueden o no pueden rastrear según las directivas de robots.txt.
¿Por qué es una buena práctica para SEO incluir tu o tus sitemap/s en robots.txt aunque ya lo hayamos enviado a Google a través de Google Search Console? Aunque pueda parecer una acción redundante para Google, con la directiva sitemap nos aseguramos que no solo Google, sino también el resto de motores de búsqueda que cumplen las directivas que se indican en los archivos robots.txt (como Bing, Yahoo, etc) sepan dónde encontrar el sitemap.
Podéis encontrar las especificaciones completas de la sintaxis de robots.txt aquí: https://developers.google.com/search/reference/robots_txt?hl=es#formal-syntax-definition
Ejemplos de robots.txt óptimos para SEO
Seguramente tras leer todo lo anterior, ya tendréis en mente alguna idea para aplicar rápidamente a vuestro robots.txt y optimizar vuestro SEO. Para facilitaros la personalización de robots.txt, a continuación os mostramos varios ejemplos de configuraciones y directivas habituales que podrían mejorar el SEO de nuestros sitios:
# bloqueamos los siguientes bots poco útiles para no sobrecargar el servidor
User-agent: MSIECrawler
Disallow: /
User-agent: WebCopier
Disallow: /
User-agent: WebReaper
Disallow: /
User-agent: HTTrack
Disallow: /
User-agent: Baiduspider
Disallow: /
User-agent: GurujiBot
Disallow: /
User-agent: hl_ftien_spider
Disallow: /
User-agent: libwww
Disallow: /
User-agent: sogou spider
Disallow: /
User-agent: Yeti
Disallow: /
User-agent: YodaoBot
Disallow: /
# bloqueamos páginas que no se deberían rastrear para optimizar nuestro crawl-budget, como la página de gracias tras enviar un formulario, o los textos legales:
User-agent: *
Disallow: /gracias
Disallow: /aviso-legal
Disallow: /politica-de-privacidad
Disallow: /politica-de-cookies
# evitamos que se rastreen por Googlebot-Image las imágenes en formato gif, que no serán indexadas en Google imágenes:
User-agent: Googlebot-Image
Disallow: /*.gif$
# prevenimos problemas de recursos bloqueados en Google Webmaster Tools
User-Agent: Googlebot
Allow: /*.css$
Allow: /*.js$
# indicamos la localización de nuestro/s sitemap/s
Sitemap: https://example.com/sitemap.xml
Sitemap: https://example.com/sitemap-imagenes.xml
El anterior ejemplo pretende mostrar muchas de las casuísticas típicas que esperamos os sea de ayuda para confeccionar vuestro robots.txt personalidado. En la URL de Google developers que os dejamos a continuación, podéis encontrar más ejemplos y reglas de robots.txt habituales que os pueden resultar útiles: https://developers.google.com/search/docs/advanced/robots/create-robots-txt?hl=es#reglas-%C3%BAtiles-de-robots.txt
Cómo probar el funcionamiento de robots.txt
Con un robots.txt optimizado podemos mejorar nuestro SEO, pero ojo, con un robots.txt incorrecto, también podemos cargárnoslo…
Para evitar esto, y ayudarnos con la optimización y testing de robots.txt , Google puso a nuestra disposición en Search Console la herramienta «Probador de robots.txt» (https://www.google.com/webmasters/tools/robots-testing-tool) que nos muestra si el archivo robots.txt publicado bloquea el acceso de los boots de rastreo de Google a URLs concretas de nuestro sitio web.
La herramienta también nos permite comprobar la sintaxis, informándonos de errores y advertencias, introducir cambios en el robots.txt con su editor, y enviar una solicitud a Google para informar que hemos actualizado el archivo robots.txt.
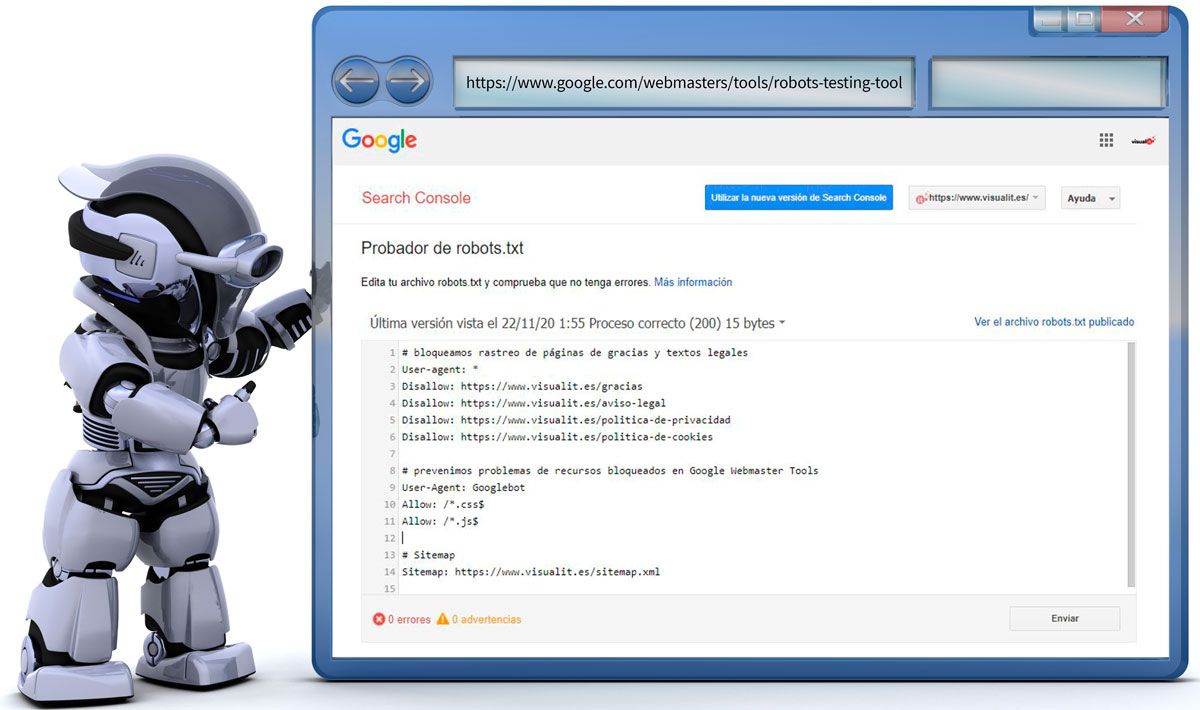
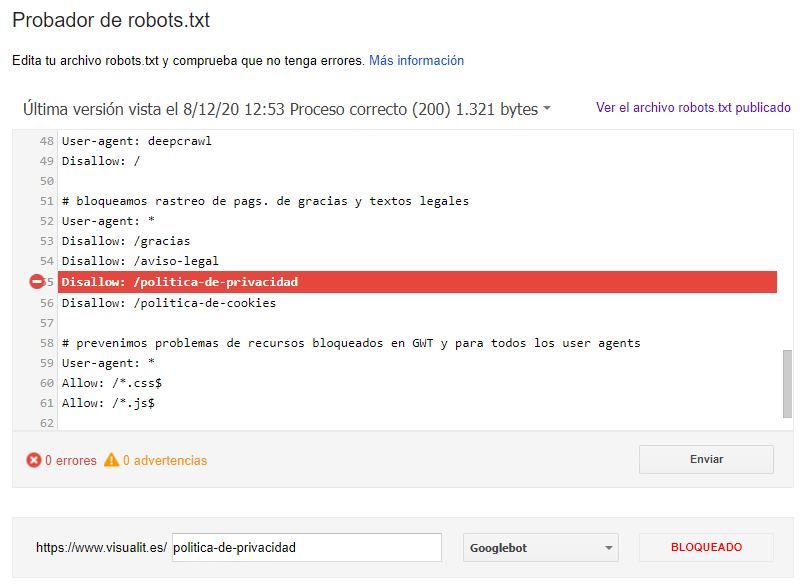
Con esta herramienta podremos comprobar además, si los bloqueos que estamos indicando, funcionan o no cómo habíamos previsto, asegurándonos que son accesibles para Google las URLs que queremos que sigan siendo accesibles, y también que un bloqueo que hemos definido con Disallow funciona como estaba previsto, como comprobamos a continuación:
Además de la herramienta de Google Search Console, también hay otras, como el validador y herramienta de testing de robots.txt de technicalseo.com: https://technicalseo.com/tools/robots-txt/, que desde aquí os recomendamos, y con el que podréis validar o complementar vuestras pruebas en caso de dudas.
Esperamos que este artículo os haya sido de utilidad, y que hayamos despertado en vosotros el interés por optimizar ese pequeño archivo llamado robots.txt, con el que podemos conseguir una mejora importante en nuestro SEO.
¿Necesitáis ir un paso más allá en la optimización del SEO técnico de vuestra Web? Recordar que podéis contar con el equipo de Visualit para llevarlo a cabo, y pondremos a vuestro servicio todo nuestro saber hacer y la experiencia de nuestros especialistas SEO para conseguir los objetivos de tu proyecto.
A continuación os dejamos con las referencias, así como con recursos muy interesantes para que podáis seguir profundizando en el conocimiento de robots.txt.
Recursos:
- Cómo probar tu archivo robots.txt con el Probador de robots.txt: https://support.google.com/webmasters/answer/6062598?hl=es
- Herramienta probador de robots.txt en Google Search Console: https://www.google.com/webmasters/tools/robots-testing-tool
- Validador y herramienta de testing de robots.txt de technicalseo.com: https://technicalseo.com/tools/robots-txt/
Referencias:
- Usos y limitaciones de los archivos robots.txt: https://developers.google.com/search/docs/advanced/robots/intro?hl=es
- Rastreadores de Google (user agents): https://developers.google.com/search/docs/advanced/crawling/overview-google-crawlers
- Preguntas frecuentes sobre robots.txt: https://developers.google.com/search/docs/advanced/robots/robots-faq?hl=es#h12
- Especificaciones de Robots.txt: https://developers.google.com/search/reference/robots_txt
- What Crawl Budget Means for Googlebot https://developers.google.com/search/blog/2017/01/what-crawl-budget-means-for-googlebot
- El analizador de robots.txt de Google ahora es de código abierto: https://developers.google.com/search/blog/2019/07/repp-oss